3. Forms
The current TEI Guidelines allows for an extremely wide range of encoding possibilities for written and spoken forms. In the discussion which follows, we suggest ways in which the elements, in particular <form>, can be constrained. We give examples of use types not covered by the Guidelines, and propose some extensions.
3.1. A note on inheritance
We assume that in order to determine the complete properties of an element inside the entry tree, the principle of default inheritance applies, e.g. grammatical properties of a form are determined by collecting the sibling <gramGrp> of the ancestor-or-self of the focus element, where the superordinate grammatical properties can be overwritten by the lower-level properties. This principle is relatively straightforward in the case of grammatical properties, but more complex for the word paradigm, esp. in cases of variant forms. For more information c.f. Ide et al. (2000) and Erjavec et al. (2000).
3.2. Lemmas
The form element should always be qualified by its type. The lemma (i.e. headword) form should be encoded as form[@type="lemma"].
If it is necessary to specify the grammatical properties of the lemma form itself (as opposed to the grammatical properties of the entry), this is described by entry/form[@type="lemma"]/gramGrp.
3.3. Inflected forms
Dictionaries often include additional forms next to the lemma. In English, these are used to specify irregular forms, such as “corpus / corpora” or “take / took”, whereas in inflectionally rich languages they are often used to help the user determine the correct paradigm of the word.
Such inflected forms should be encoded in entry/form[@type="inflected"], e.g.:
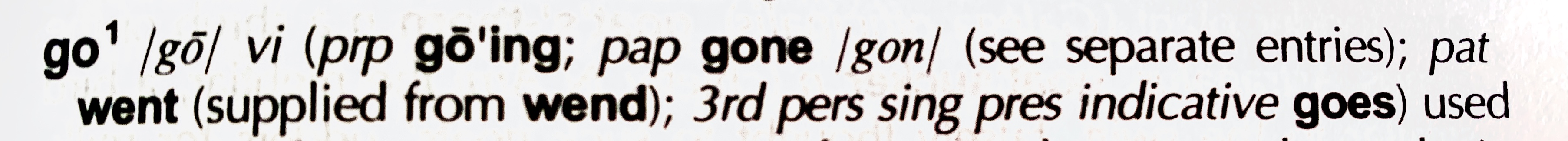
<entry xml:lang="en" xml:id="CH.go1">
<form type="lemma">
<orth>go</orth>
<pron>gō</pron>
</form>
<lbl rend="sup">1</lbl>
<gramGrp>
<gram type="pos">vi</gram>
</gramGrp>
<pc>(</pc>
<form type="inflected">
<gramGrp>
<gram type="participle">prp</gram>
</gramGrp>
<orth>gō'ing</orth>
</form>
<pc>;</pc>
<form type="inflected">
<gramGrp>
<gram type="participle">pap</gram>
</gramGrp>
<orth>gone</orth>
<pron>gon</pron>
<note>(see separate entries)</note>
</form>
<pc>;</pc>
<form type="inflected">
<gramGrp>
<gram type="participle">pat</gram>
</gramGrp>
<orth>went</orth>
<note>(supplied from <xr type="related">
<ref type="entry">wend</ref>
</xr>)</note>
</form>
<pc>;</pc>
<form type="inflected">
<gramGrp>
<gram type="person">3rd</gram>
<gram type="tense">pers</gram>
<gram type="number">sing</gram>
<gram type="tense">pres</gram>
<gram type="mood">indicative</gram>
</gramGrp>
<orth>goes</orth>
</form>
<pc>;</pc>
<!--...-->
</entry>Chambers (2011) Or take this example: abeceda, -y: in Czech, "-y" is a genitive singular suffix for feminine nouns. We can mark-up the grammatical properties of the suffix, while providing the full form of the noun as well:
<entry type="mainEntry" xml:lang="cz" xml:id="en000008">
<form type="lemma" xml:id="en000008.hw1">
<orth>abeceda</orth>
</form>
<pc>,</pc>
<form type="inflected">
<gramGrp>
<gram type="case" value="genitiv"/>
<gram type="number" value="singular"/>
<gram type="gender" value="feminine"/>
</gramGrp>
<orth extent="suffix" expand="abecedy">-y</orth>
</form>
<!--...-->
</entry>3.4. Paradigms
When several inflected forms can be present next to the lemma, these can be embedded into entry/form[@type="paradigm"]. The decision on whether to use this extra element depends on the particular dictionary and language.
The other use case for paradigms is when the full inflectional paradigm of the word is embedded in the entry, i.e. when the dictionary also includes all the word-forms of the words covered, which can be useful for example in machine processing.
An entry may contain several paradigms, e.g. a partial one for humans and a full one for machines, or one for each stem of a verb. Each paradigm type should be distinguished by the subtype attribute.
<entry xml:id="perder" xml:lang="es">
<form type="lemma">
<orth>perder</orth>
</form>
<gramGrp>
<gram type="pos">verb</gram>
</gramGrp>
<form type="paradigm" subtype="present">
<form type="inflected">
<orth>pierdo</orth>
<gramGrp>
<gram type="person">1</gram>
<gram type="number">sg</gram>
<gram type="mood">indic</gram>
<gram type="voice">active</gram>
</gramGrp>
</form>
<!-- other inflected forms (of present indicative) here -->
<gramGrp>
<gram type="tns">present</gram>
</gramGrp>
</form>
<form type="paradigm" subtype="preteritum">
<form type="inflected">
<orth>perdí</orth>
<gramGrp>
<gram type="person">1</gram>
<gram type="number">sg</gram>
<gram type="mood">indic</gram>
<gram type="voice">active</gram>
</gramGrp>
</form>
<gramGrp>
<gram type="tense">preteritum</gram>
</gramGrp>
</form>
<!--... -->
</entry>3.5. Variants
The representation of variation within a form is highly dependant upon the specifics of the features of the variation and the way in which they vary. However, as a general principle, variation may be encoded as form[@type="variant"] and embedded within the parent element for which a subordinate feature exhibits variation.
3.5.1. Orthographic variation
Several kinds of orthographic variation may be distinguished. Below, we present some of the options with the corresponding examples.
Spelling variation due to change in language’s orthography convention:
<entry xml:id="Flussschifffahrt" xml:lang="de" type="compound">
<form type="lemma">
<orth type="segmented">
<seg>Fluss</seg>
<seg>schifffahrt</seg>
</orth>
<form type="variant">
<orth>
<seg>Fluss</seg>
<pc>-</pc>
<seg>Schifffahrt</seg>
</orth>
</form>
<form type="variant">
<orth notAfter="1996">
<seg>Fluß</seg>
<seg>schiffahrt</seg>
</orth>
<usg type="temporal">Vor 1996 Rechtschreibung Reform</usg>
</form>
<gramGrp>
<gram type="pos">noun</gram>
</gramGrp>
</form>
<!--...-->
</entry>The following example is from American English in which due to the lack of official conventions for transliteration of Arabic orthography to the English (Latin) script, the initial vowel in the surname ‘Osama Bin Laden’ varies between ‘O’ and ‘U’:
<entry xml:id="Osama" xml:lang="en">
<form type="lemma">
<pron notation="ipa">
<seg xml:id="ousma" corresp="#usma #osma">ow."sa.ma</seg>
<seg>bɪn</seg>
<seg>ˈlaːdn̹</seg>
</pron>
<form type="variant">
<orth type="transliterated">
<seg xml:id="osma" corresp="#usma #ousma">Osama</seg>
<seg>Bin</seg>
<seg>Laden</seg>
</orth>
</form>
<form type="variant">
<orth type="transliterated">
<seg xml:id="usma" corresp="#osma #ousma">Usama</seg>
<seg>Bin</seg>
<seg>Laden</seg>
</orth>
</form>
</form>
<!--...-->
</entry>3.5.2. Phonetic variation
In this example, the entry contains the single orthographic form as a direct child of the lemma and phonetic transcriptions of the two roughly equally used variant pronunciations of the word 'caramel' from American English.
<entry xml:id="caramel-en" xml:lang="en-US">
<form type="lemma">
<orth>caramel</orth>
<form type="variant">
<pron notation="ipa">'keɹə"mɛl</pron>
</form>
<form type="variant">
<pron notation="ipa">'kaɹmɫ̩</pron>
</form>
</form>
<gramGrp>
<gram type="pos">noun</gram>
</gramGrp>
<!-- ... -->
</entry>In the example above, one could have chosen to mark up two different pronunciations using two <pron> elements inside the form[@type="lemma"]. Considering, however, that each individual pronunciation could, in theory, be further qualified, for instance, by a <usg> note, indicating the geographic area in which the said pronunciation is used, TEI Lex-0 recommends that multiple variants, whether orthographic or orthoepic, be contained each in its own <form> element.
3.5.3. Regional or dialectal variation
In the following example from Mixtepec-Mixtec, there is variation in the form of the word for the city of Oaxaca between speakers from the village of Yucanany and the rest of the speakers. Since the Yucanany variety makes up only a small portion of the speakers of the language, this case of variation is represented as an embedded form[@type="variant"] within the lemma. Note the use of usg[@type="geographic"]/placeName to explicitly specify this feature in addition to the use of the private language subtag (@xml:lang="mix-x-YCNY") as per BCP 47.
<entry xml:id="Oaxaca-MIX" xml:lang="mix" type="compound">
<form type="lemma">
<orth>
<seg>Ñuu</seg>
<seg>Ntua</seg>
</orth>
<pron notation="ipa">
<seg>ɲùù</seg>
<seg>nd̪ùá</seg>
</pron>
<form type="variant" xml:lang="mix-x-YCNY">
<orth>Ntua</orth>
<pron notation="ipa">nd̪ùá</pron>
<usg type="geographic"> Yucanany </usg>
</form>
</form>
<gramGrp>
<gram type="pos">locationNoun</gram>
</gramGrp>
<!--...-->
</entry>3.6. Condensed forms
In some lexicographic traditions, it is common to encounter dictionary entries that conflate two or more distinct lemmas into a single entry headword. A frequent example of this is the combination of a base verb and its reflexive variant in Savic languages. While such pairings may suggest morphological or derivational relationships, they are more than just inflectional variants: they can sometimes represent distinct lexical items, each with its own semantics and usage.
To illustrate this phenomenon, consider the Old Czech verb leleti and its reflexive counterpart leleti sě. These can be presented in a print dictionary in a condensed, shorthand form such as leleti (sě).

In English, this would be comparable to a hypothetical lemma ask (oneself) combining ask (“to pose a question”) and ask oneself (“to wonder, to reflect”) in a single entry as one condensed lemma.
Because bracketed constructions such as leleti (sě) do not represent naturally occurring word forms, we recommend treating these condensed forms as labels (<lbl>) rather than lemmas. From an encoding perspective, this means using lbl[@type="condensedLemma"] to represent the compacted headword for display or identification purposes, while defining each of the component lemmas separately using individual <form> elements:
<entry xml:lang="cs-x-old" type="mainEntry" xml:id="MSS.leleti">
<lbl type="condensedLemmas">leleti (sě)</lbl>
<form type="lemma" resp="#boris">
<orth value="leleti"/>
</form>
<form type="lemma" resp="#boris">
<orth value="leleti sě"/>
</form>
<metamark function="delimiter">, </metamark>
<lbl type="condensedInflectedForms">-eju, -éš (sě)</lbl>
<form type="inflected" resp="#boris">
<orth value="leleju"/>
<gramGrp>
<gram type="person" value="1"/>
<gram type="number" value="singular"/>
<gram type="tense" value="present"/>
<gram type="mood" value="indicative"/>
</gramGrp>
</form>
<form type="inflected" resp="#boris">
<orth value="lelejéš"/>
<gramGrp>
<gram type="person" value="2"/>
<gram type="number" value="singular"/>
<gram type="tense" value="present"/>
<gram type="mood" value="indicative"/>
</gramGrp>
</form>
<form type="inflected">
<orth value="leleju sě" resp="#boris"/>
<gramGrp>
<gram type="person" value="1"/>
<gram type="number" value="singular"/>
<gram type="tense" value="present"/>
<gram type="mood" value="indicative"/>
<gram type="valency" value="reflexive"/>
</gramGrp>
</form>
<form type="inflected">
<orth value="lelejéš sě" resp="#boris"/>
<gramGrp>
<gram type="person" value="2"/>
<gram type="number" value="singular"/>
<gram type="tense" value="present"/>
<gram type="mood" value="indicative"/>
<gram type="valency" value="reflexive"/>
</gramGrp>
</form>
<gramGrp>
<gram type="aspect" expand="nedokonavé" value="imperfective">ned.</gram>
<gram type="pos" value="verb"/>
</gramGrp>
<sense xml:id="MSS.leleti.sense.1">
<def>vlnit (se), kolébat (se)</def>
</sense>
</entry>Bělič et al. (1979) Above, the value attribute is used to supply reconstructed or editorially inferred lemma forms that do not appear explicitly in the print source. This distinction is crucial for digital representations of legacy lexica, where not all valid headwords are explicitly listed in the original. In TEI Lex-0, it is common to encode lemmas that are not physically present in the printed source using the value attribute on <orth>, rather than placing the text directly as content within the element.
If we encode regular lemmas (those present in the source) as //form[@type='lemma']/orth and reconstructed lemmas (those inferred or editorially supplied) as //form[@type='lemma']/orth/@value, we will no longer have a uniform path for indexing the dictionary. This is because two kinds of lemmas will reside on different XPaths. This, however, is a necessary and principled compromise.
The suggested encoding and expansion of condensed lemmas allow users and systems to reconstruct the full lemma inventory of a dictionary, including analytically significant forms absent from the source. At the same time, they make explicit which forms are present in the original and which have been editorially supplied, thus preserving presentational fidelity to the print source while enhancing searchability, machine processing, and downstream applications.
To support robust querying, it is, therefore, recommended that documentation or downstream systems account for this distinction, for instance by using the combined XPath expression such as //form[@type='lemma']/orth/text() | //form[@type='lemma']/orth/@value to get to the consolidated list of both explicit and implicit lemmas.
3.7. Multiword expressions
The Dictionary Chapter of the TEI Guidelines is very sparse when it comes to recommendations for encoding polylexical units. The only mention of the adjective “multi-word” appears in the definition of the element <term>: “contains a single-word, multi-word, or symbolic designation which is regarded as a technical term” but this is not relevant for the encoding of polylexical units in general-purpose dictionaries.
TEI includes an element <colloc> (collocate), which is defined as containing “any sequence of words that co-occur with the headword with significant frequency” but, in a different example, “colloc” is used as an attribute value for the element <usg> (usage). It is precisely this type of ambiguity that TEI Lex-0 is trying to resolve.
The TEI Guidelines recommend the use of <re> (related entry) to encode “related entries for direct derivatives or inflected forms of the entry word, or for compound words, phrases, collocations, and idioms containing the entry word” with barely any useful examples, or discussion of how to encode different types of polylexical units. TEI Lex-0, on the other hand, does not include <re>. In TEI Lex-0, <entry> was made recursive in order to account for nestable entry-like structures without the need to resort to <re>, a differently named element whose content model would be indistinguishable from <entry> itself. Eventually, the new content model of <entry>, which allows nesting, was adopted by TEI itself (Tasovac 2020).
TODO: explain different types of mwe's from a dict. model perspective referring to Tasovac 2020)
3.7.1. Collocations
TODO: explain "lexicographically transparent"

<entry xml:id="DLPC.descalçar" xml:lang="pt">
<!--etc.-->
<sense xml:id="DLPC.descalçar.1">
<!--etc.-->
<form type="collocations">
<form type="collocation">
<orth>
<ref type="form" scope="currentEntry" value="descalçar">
<metamark>+</metamark>
</ref>
<seg>as botas</seg>
</orth>
<gramGrp>
<gram type="mwe" value="co-ocorrente_privilegiado"/>
</gramGrp>
</form>
<pc>,</pc>
<form type="collocation">
<orth>
<ref type="form" scope="currentEntry" value="descalçar"/>
<seg>as luvas</seg>
</orth>
<gramGrp>
<gram type="mwe" value="co-ocorrente_privilegiado"/>
</gramGrp>
</form>
<pc>,</pc>
<form type="collocation">
<orth>
<ref type="form" scope="currentEntry" value="descalçar"/>
<seg>as meias</seg>
</orth>
<gramGrp>
<gram type="mwe" value="co-ocorrente_privilegiado"/>
</gramGrp>
</form>
</form>
<pc>;</pc>
<form type="collocations">
<form type="collocation">
<orth>
<ref type="form" scope="currentEntry" value="descalçar">
<metamark>+</metamark>
</ref>
<seg>os sapatos</seg>
</orth>
<gramGrp>
<gram type="mwe" value="co-ocorrente_privilegiado"/>
</gramGrp>
</form>
</form>
<pc>.</pc>
</sense>
</entry>DLPC (2001) 3.7.2. Idiomatic expressions
TODO text ("lexicographically non-transparent")

<entry xml:lang="pt" xml:id="DLPC.bombeiro" type="mainEntry">
<form type="lemma">
<orth>bombeiro</orth>
</form>
<!--etc. -->
<sense xml:id="bombeiro.1">
<!--etc. -->
<entry xml:id="DLPC.bombeiro_voluntario" xml:lang="pt" type="relatedEntry">
<form type="lemma">
<orth>bombeiro voluntário</orth>
</form>
<gramGrp>
<gram type="mwe" value="combinatória_fixa"/>
</gramGrp>
<pc>,</pc>
<sense xml:id="DLPC.bombeiro_voluntario.1">
<def>o que pertence a uma corporação com a obrigatoriedade de acudir a incêndios, acidentes, unicamente por filantropia</def>
<pc>.</pc>
</sense>
</entry>
<entry xml:id="DLPC.corpo_de_bombeiros" xml:lang="pt" type="relatedEntry">
<form type="lemma">
<orth>
<ref type="entry" scope="currentEntry">
<seg>corpo</seg>
<metamark rend="sup">+</metamark>
</ref>
<seg>de bombeiros</seg>
</orth>
</form>
<pc>.</pc>
</entry>
</sense>
<!--etc.-->
</entry>DLPC (2001) 

